Here is the result of a bogomflop run on metatron. Note the significant difference between this benchmark on an AMD64 and on a P4 such as lucifer. On lucifer I got 162 bogomflops at a clock of 1.8 GHz, vs 455 bogomflops at a clock of 2.4 GHz here. 2.75 times as fast with a clock only 1.33 times as fast -- beating clock by more than a factor of two.
This is quite understandable. Wider registers mean that division requires fewer instructions and a lot less work.
Does this mean that your code would run much faster on an AMD64? Not necessarily. For example, it might not have much division in it, and the division operation is by far the rate limiter here. If you do a lot of floating point division, though, it might.
rgb@metatron|B:1178>./benchmaster -t 1 -s 2000000 #========================================================================== # Benchmaster 1.0.1 # Copyright 2004 Robert G. Brown # #========================================================================== # Host Information # hostname: metatron compiler/flags: gcc -O3 # CPU: AuthenticAMD AMD Athlon(tm) 64 Processor 3400+ at 2411.773 (MHz) # CPU: L2 cache: 512 KB bogomips: 4767.74 # Total Memory: 509720 (Current) Free Memory: 131256 # cpu cycle counter nanotimer: clock granularity (nsec/cycle) = 3.009 #========================================================================== # Test Information # Test: bogomflops # Description: d[i] = (ad + d[i])*(bd - d[i])/d[i] (8 byte double vector) # # Number of samples: 100 xtest: 3.141593 vector order: unshuffled # full iterations = 2 empty iterations = 524288 # time full = 17576378.925380 (nsec) time empty = 3.334081 (nsec) # # test name vlen stride time +/- sigma (nsec) megarate #========================================================================== "bogomflops" 2000000 1 2.20e+00 8.17e-04 4.552e+02Back to top
Another interesting example where the AMD64 exceeds clock is in transcendental function evaluation. To remind you, on lucifer (P4 at 1.8 GHz) I obtained a 1.66 megasavage rate. On metatron (AMD64 at 2.4 GHz) I get a whopping 6.14, 3.7 times faster and almost 3 times its clockspeed advantage. One would guess that as before, wider registers permit division and multiplication to proceed much faster internally as various series are summed to produce the transcendental function results.
Also as before, this might mean exactly nothing to you if your code is not transcendental rich, or the world to you if you are doing a lot of trigonometric function evaluation or exponentiation.
rgb@metatron|B:1180>./benchmaster -t 9 #========================================================================== # Benchmaster 1.0.1 # Copyright 2004 Robert G. Brown # #========================================================================== # Host Information # hostname: metatron compiler/flags: gcc -O3 # CPU: AuthenticAMD AMD Athlon(tm) 64 Processor 3400+ at 2411.773 (MHz) # CPU: L2 cache: 512 KB bogomips: 4767.74 # Total Memory: 509720 (Current) Free Memory: 130408 # cpu cycle counter nanotimer: clock granularity (nsec/cycle) = 3.013 #========================================================================== # Test Information # Test: savage # Description: xtest = tan(atan(exp(log(sqrt(xtest*xtest))))) # # Number of samples: 100 xtest: 3.141593 vector order: unshuffled # full iterations = 4096 empty iterations = 8192 # time full = 331.242584 (nsec) time empty = 168.345198 (nsec) # # test name vlen stride time +/- sigma (nsec) megarate #========================================================================== "savage" 1000 1 1.63e+02 3.13e-01 6.139e+00Back to top
The read/write benchmark is again run twice, the second time the vector order is shuffled, defeating the cache. The graph reveals a lot about the performance of the AMD64 at moving data around. Compare again to the lucifer (P4) results.
rgb@metatron|B:1852>log-plot-benchmaster -t 6 > metatron_unshuffled_rw.data rgb@metatron|B:1858>log-plot-benchmaster -t 6 -r > metatron_shuffled_rw.data
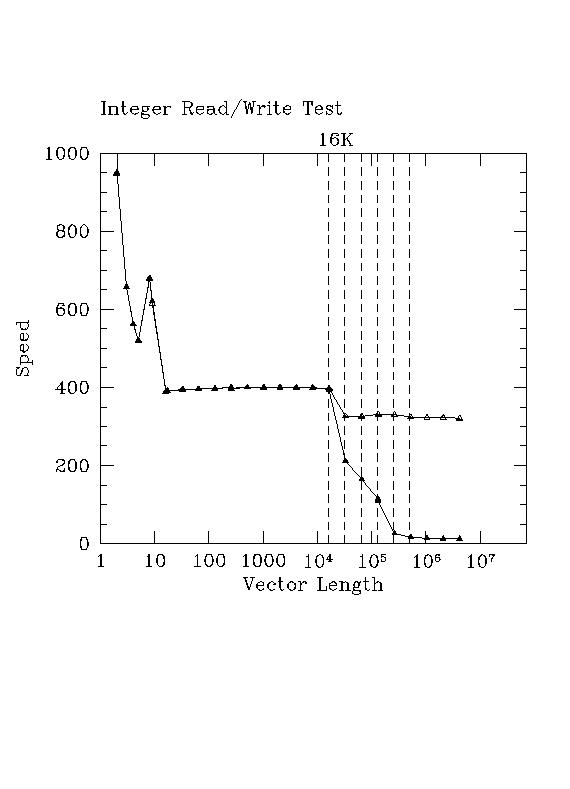
In this figure, open triangles are unshuffled and filled triangles are shuffled order. Notice the complete absence of "sawtoothing" -- data movement no longer depends on whether one is moving an odd or even number of integer words.
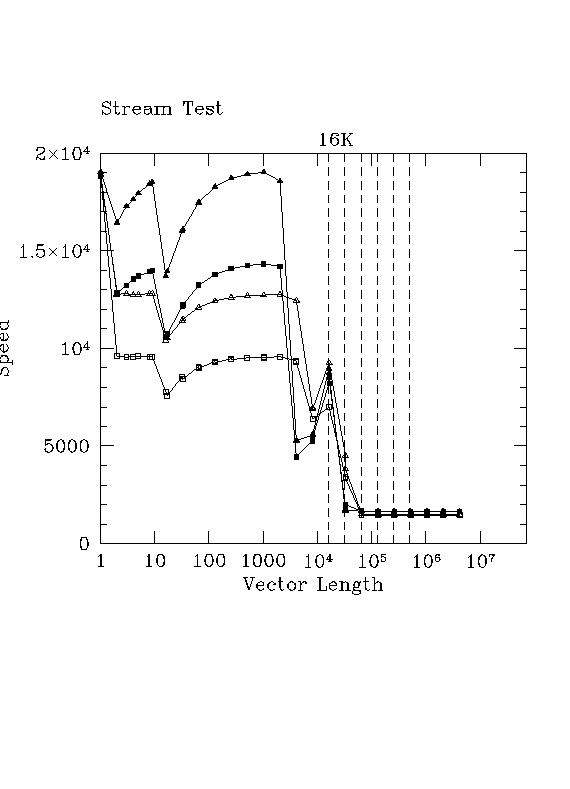
Back to topThe stream results are extremely interesting. As one can see below, the stream results (with gcc -O3!) just barely beat clockspeed scaling relative to lucifer (the P4).
This points to one of the many dangers of using any single measure of performance to make e.g. purchase decisions. If one naively generated and compared stream results, one might conclude that the AMD64 isn't likely to outperform a P4 at roughly the same price on any code, and as we've seen above, that is simply not true for people who are running code that involves division and/or transcendental function calls.
It does leave us with something to understand. There are a number of possible explanations, but the simplest one is that the gcc compiler, at "just" -O3, is not really optimizing the code for stream-like operations. In particular, it may not be prefetching loop arrays. Another very distinct possibility is that these results are obtained un a spanking new Fedora Core 3 installation, which is still using gcc 3.4.2 and may not yet be numerically optimized for the X86_64 architecture.
This is one of the points in having the source of the benchmark code. If you have a variety of compilers and flags to choose from, you can vary them and see if they make any difference.
rgb@metatron|B:1184>stream.sh #========================================================================== # Benchmaster 1.0.1 # Copyright 2004 Robert G. Brown # #========================================================================== # Host Information # hostname: metatron compiler/flags: gcc -O3 # CPU: AuthenticAMD AMD Athlon(tm) 64 Processor 3400+ at 2411.773 (MHz) # CPU: L2 cache: 512 KB bogomips: 4767.74 # Total Memory: 509720 (Current) Free Memory: 130008 # cpu cycle counter nanotimer: clock granularity (nsec/cycle) = 3.020 #========================================================================== # Emulating John D. McCalpin's stream benchmark # # test name vlen stride time +/- sigma (nsec) Rate (MB/sec) #========================================================================== "stream copy" 2000000 1 1.07e+01 7.03e-03 1.500e+03 "stream scale" 2000000 1 1.11e+01 3.80e-03 1.449e+03 "stream add" 2000000 1 1.46e+01 1.82e-02 1.651e+03 "stream triad" 2000000 1 1.46e+01 2.76e-03 1.642e+03Back to top
It is useful to again compare the stream curves below to those for the P4, where open triangle is copy, open square is scale, filled triangle is add, and filled square is triad. One observes "better" behavior in many ways in cache, but not a significant advantage when running out of memory.